




Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Reloading full datasets every time data updates?
That’s a recipe for bloated pipelines, wasted compute, and missed insights. Incremental loading solves that by moving only what’s changed, nothing more, nothing less. It’s faster, leaner, and built for modern data needs.
This blog breaks down Microsoft Fabric incremental load strategies that actually work. You’ll learn how to implement Change Data Capture (CDC), use timestamp filtering, configure incremental refresh with Dataflow Gen2, and build efficient Data Factory pipelines. Every technique is explained with hands-on clarity, no fluff, just what you need to build smarter, scalable data systems.
Incremental loading refers to the process of updating only the new or changed data in a destination, rather than performing a full data reload. It's especially useful when working with large datasets, time-sensitive applications, or frequent data refreshes.
Key Benefits:
Common techniques include:
Incremental load in Microsoft Fabric helps you move only new or updated data, so you don't have to reload everything. This approach boosts performance, cuts compute costs, and delivers faster insights. Let’s break down how to set up incremental data movement from a Data Warehouse to a Lakehouse using Fabric’s Data Factory pipeline.
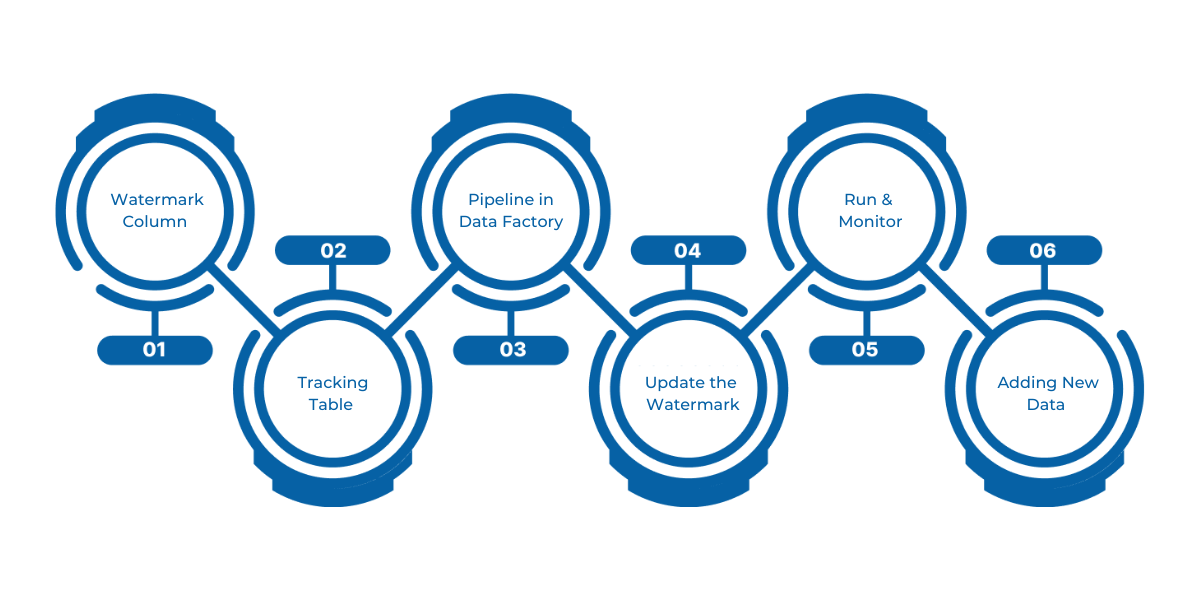
The first step is choosing a column (like LastModifytime) that indicates changes in the source table. This column acts as a watermark, identifying new or updated records since the last pipeline run.
A simple table (watermarktable) in your Data Warehouse stores the last known watermark value. This acts as a reference point for your next incremental load.
create table watermarktable (
TableName varchar(255),
WatermarkValue DATETIME2(6)
);
You’ll insert an initial default value, such as:
INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM');
Build a pipeline in Microsoft Fabric's Data Factory using the following activities:
WHERE LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}'
AND LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'
After a successful copy, use a Stored Procedure Activity to update the watermark value in watermarktable, setting it to the newly captured maximum value.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET WatermarkValue = @LastModifiedtime
WHERE TableName = @TableName
END
Trigger the pipeline. After execution, check your Lakehouse folder to verify that a new data file with the incremental records has been created.
To validate incremental logic:
Incremental data loads in Microsoft Fabric offer a resource-efficient way to keep your Lakehouse in sync with source systems.
Ideal for time-series data, logs, and transactional records, this approach ensures your analytics stay fresh, without the cost of full reloads.
While a basic pipeline setup helps you handle incremental loads for a single table, scaling that logic across multiple datasets can become tedious. Microsoft Fabric supports a more modular and automated approach using a combination of Lakehouses, JSON-based config files, notebooks, and dynamic pipeline activities, perfect for large-scale or growing data environments.
This method enables data engineers to maintain a clean, extensible structure that scales with evolving business requirements.
Here’s a breakdown of the scalable incremental load process using Microsoft Fabric Data Factory and notebooks:
Rather than relying on an external database, this method demonstrates how to use two Fabric Lakehouses, one as the source and the other as a staging area. This keeps everything within Fabric’s unified environment, optimizing speed and simplifying governance.
Instead of hardcoding table names or watermark values, you maintain a JSON config file that tracks the last_updated timestamp for each table. This file is stored in the Lakehouse (not as a table, but as a file) and allows pipelines to loop over multiple tables without manual changes.
Example config.json:
[
{
"table_name": "customers",
"last_updated": "2024-01-04 08:11:07"
},
{
"table_name": "orders",
"last_updated": "2024-01-04 08:11:07"
}
]
This approach dramatically reduces maintenance overhead, you simply update the config file to onboard new tables.
In the Data Factory pipeline:
Within the loop, a notebook activity is invoked with parameters:
Sample notebook logic using PySpark:
delta_table_path = f"abfss://<your_workspace_name>@onelake.dfs.fabric.microsoft.com/<Lakehouse>.Lakehouse/Tables/{table}"
df = spark.read.format("delta").load(delta_table_path)\
.filter(f"last_updated >= '{last_updated}' AND last_updated < '{max_updated}'")
This filters only the new or updated records between two points in time.
After successful processing, the pipeline updates the same config.json with the latest last_updated timestamp, ensuring the next run starts from the correct point.
for item in data:
item["last_updated"] = new_time
This automated approach ensures your incremental loads stay accurate and continuous, no manual fixes required. With a config-driven setup, notebooks, and Fabric’s Lakehouse, teams can scale across datasets without hardcoding or duplication.
Whether migrating existing workloads or building new ones, this technique delivers the flexibility and automation today’s data platforms need.

Dataflow Gen2 in Microsoft Fabric simplifies incremental loading by automating the detection of new or changed records, no manual tracking of timestamps or watermarks needed. Ideal for large-scale data ingestion and transformation, it streamlines performance and reduces engineering overhead with built-in refresh logic.
Incremental refresh in Dataflow Gen2 means only new or changed data is processed and loaded, rather than reloading the entire dataset each time. This offers:
It’s particularly well-suited for scenarios like transactional systems, time-series data, or large-scale reporting pipelines.
To use this feature, you must:
Supported data destinations include:
Other destinations can still benefit from this feature if paired with a staging query.
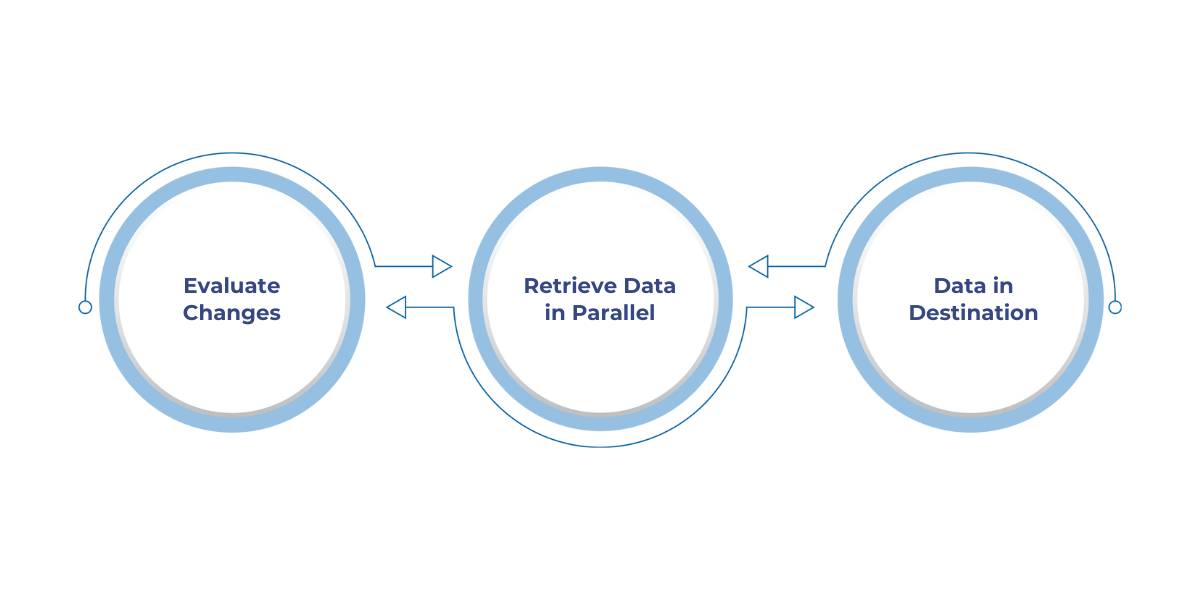
Incremental refresh works by dividing data into buckets using a chosen DateTime column. Here's how the process unfolds:
When setting up incremental refresh, you’ll define:
There are also advanced options, such as requiring the query to fully fold (highly recommended for performance).
Some caveats apply when using Dataflow Gen2 with Lakehouse:
Dataflow Gen2 makes incremental refresh a first-class feature:
Dataflow Gen2 incremental refresh is a code-free, intuitive solution for managing Microsoft Fabric incremental load. Building dashboards, running ML pipelines, or maintaining operational reporting, this feature keeps your data current without overloading systems.
If you’re already using Power BI or Fabric Lakehouse, this approach offers a smart, low-friction way to stay efficient as your data grows.
One of the most reliable ways to implement microsoft fabric incremental load patterns, especially for SQL-based sources, is by leveraging Change Data Capture (CDC). With CDC, you track inserts, updates, and deletes at the source without needing to scan the entire table.
In Microsoft Fabric (via integrated Data Factory pipelines), you can configure a CDC-based pipeline that:
Enable CDC on the source SQL table using:
EXEC sys.sp_cdc_enable_db;
EXEC sys.sp_cdc_enable_table
@source_schema = 'dbo',
@source_name = 'customers',
@supports_net_changes = 1;
Even though this was originally an Azure Data Factory setup, Fabric offers a streamlined version of this exact process:
This method is ideal when you want a reliable and low-latency sync between operational databases and analytical storage without constant full refreshes.

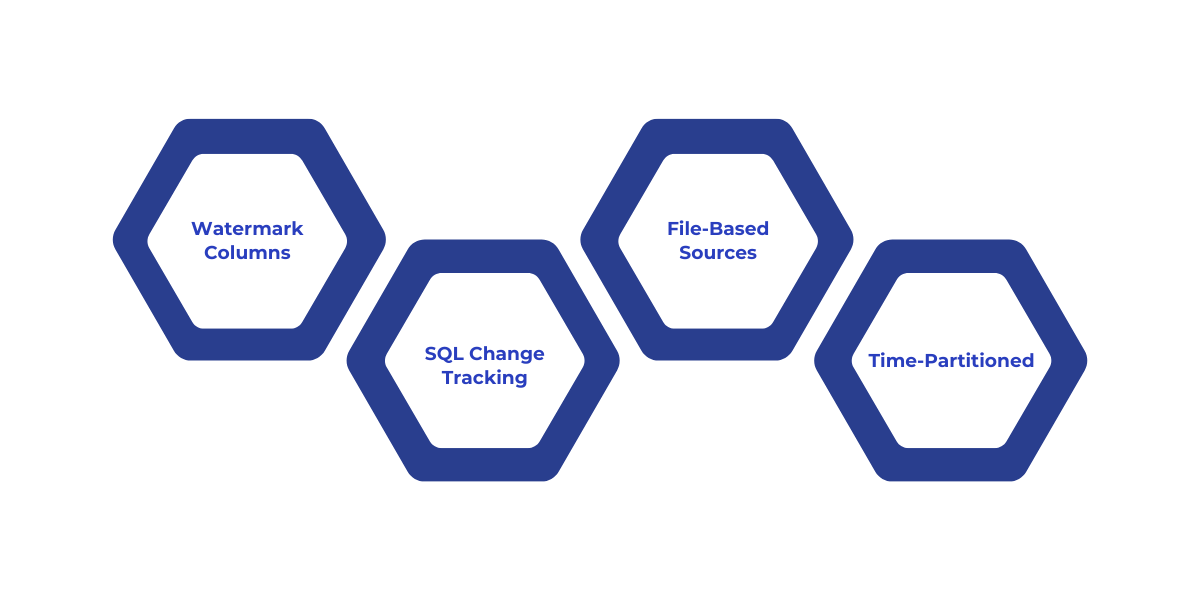
Before Microsoft Fabric unified tools like Data Factory, Synapse, and Power BI into a single platform, several incremental load techniques were commonly used across Azure services. These strategies still form the core principles behind Microsoft Fabric's incremental load capabilities today.
Here’s a quick overview of the traditional methods that Fabric now builds upon:
One of the most common patterns involves using a watermark column, such as a timestamp (LastModifiedTime) or incremental ID. This method compares old vs. new values to copy only changed data.
Example Use Cases:
SQL Server and Azure SQL Database offer a lightweight Change Tracking feature. This enables you to identify rows that were inserted, updated, or deleted without full table scans. Fabric can now ingest from sources using Change Tracking when configured via Data Factory.
When dealing with file storage (like Azure Blob or Data Lake), you can use the LastModifiedDate of files to detect and load only new or updated files. However, scanning large volumes of files, even if copying just a few, can impact performance.
If your source systems organize files in a time-based folder structure (like /2024/07/08/filename.csv), Fabric pipelines can efficiently copy only the most recent partitioned data. This is often the fastest strategy for large-scale file movement.
With the integration of Data Factory into Fabric, all of the above techniques are still relevant, but with improved accessibility. You now configure these methods directly in your Fabric workspace, taking advantage of:
Microsoft Fabric doesn't reinvent incremental loading, it simplifies, centralizes, and enhances it for modern, scalable analytics.
Implementing Microsoft Fabric incremental load techniques requires more than just technical know-how it demands precision, scalability, and alignment with your data goals.
WaferWire simplifies this process.
Our team helps you choose the right approach (CDC, timestamps, or Dataflow Gen2), set up efficient Data Factory pipelines, and optimize Lakehouse-Warehouse sync for real-time insights and lower costs.
As a Microsoft Solutions Partner, WaferWire ensures your incremental load setup is not just effective but enterprise-ready.
As data grows and demands for real-time insights increase, incremental loading becomes essential not just for performance, but for smarter, cost-effective data operations. Microsoft Fabric makes this seamless with built-in support for Change Data Capture, timestamp-based filtering, and Dataflow Gen2’s incremental refresh.
By loading only what’s changed, you cut down on compute, speed up pipelines, and keep your analytics fresh.
Looking to streamline your data architecture on Microsoft Fabric?
WaferWire helps enterprises design and implement modern data pipelines that scale.
Talk to WaferWire today to modernize with confidence.
1. What is incremental load in Microsoft Fabric?
Incremental load refers to updating only the data that has changed since the last load, avoiding a full reload of datasets. This improves performance and reduces compute costs.
2. Which Microsoft Fabric components support incremental load?
Data Factory, Dataflow Gen2, Lakehouse, and Warehouse all support incremental loading through various methods like CDC and timestamp filtering.
3. What is Change Data Capture (CDC)?
CDC is a technique that captures inserts, updates, and deletes in a source system, enabling precise and efficient incremental data movement.
4. Can I use incremental refresh with non-Microsoft data sources?
Yes, as long as the source supports query folding and includes a suitable date or timestamp column for filtering changes.
5. What’s the best way to manage multiple tables for incremental load?
Using a config file with table names and last_updated timestamps allows dynamic and scalable orchestration without hardcoding logic for each table.


